

Presentazione
Il corpus furlan è une base di dati formata da testi etichettati, ovvero a ogni parola è connessa l’informazione sul lemma da quale deriva, di che parte del discorso è, di che forma morfologica si tratta.
Attualmente il corpus consta di 486 testi per un totale che arriva poco oltre le 500.000 parole.
I testi sono in parte letterari (narrativa, teatro), in parte non letterari (informazione, divulgazione scientifica, politica ecc.).
Quasi tutti i testi erano già redatti in origine nella coinè friulana, in ogni caso sono stati sottoposti tutti a una revisione ortografica. Inoltre, per permettere al sistema informatico di processare e gestire i dati, è stata praticata una uniformazione linguistica: per esempio se nell’originale sono attestate forme come “liberamentri”, “oleve”, “e àn”, l’uniformazione ha portato a “libarementri”, “voleve”, “a àn”. A chi fosse interessato a tali livelli di differenziazione si raccomanda di consultare le fonti originali.
Nel caso di testi di interesse letterario scritti in una varietà diversa dalla coinè o in une fase della coinè friulana che presenta differenze importanti rispetto all’attuale (per esempio testi di Caterina Percoto), il programma informatico lavora su una versione uniformata del testo, ma presenta all’utente la visualizzazione della forma originale, convertita solo a livello ortografico.
Le scelte lessicali coscienti degli autori, per esempio di usare parole modificate o straniere, per conferire un effetto particolare al testo, sono state mantenute.
Consultazione
Ricerca
Tramite l’interfaccia l’utente può cercare una parola mediante la forma (qualsiasi forma flessa, per esempio van), il lemma (per esempio lâ) o la categoria grammaticale (per esempio verbo) riempiendo il relativo campo.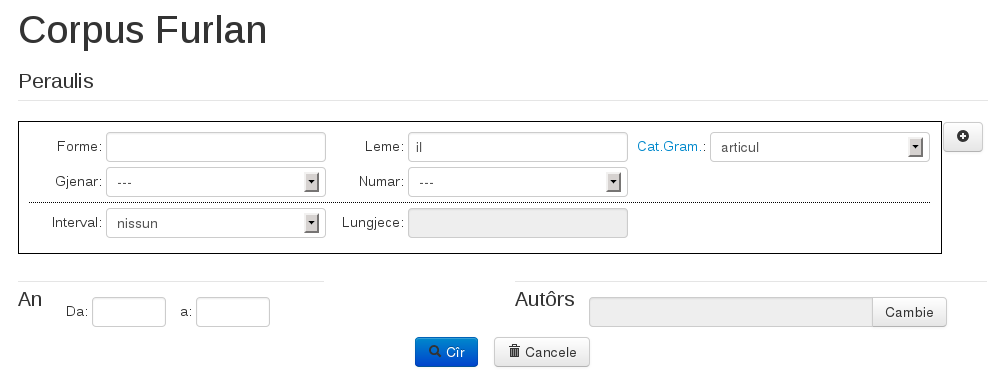 E’ anche possibile combinare più criteri di ricerca riempiendo più campi. Per esempio lemma: barbe–Cat gramaticale: sostantivo maschile oppure lemma: barbe–Cat gramaticale: sostantivo femminile.
Se viene selezionato un valore per il campo categoria grammaticale, vengono mostrati ulteriori criteri di ricerca che possono essere specificati per la categoria grammaticale scelta. Per esempio per verbo è possibile specificare modo, tempo e persona, etc.:
E’ anche possibile combinare più criteri di ricerca riempiendo più campi. Per esempio lemma: barbe–Cat gramaticale: sostantivo maschile oppure lemma: barbe–Cat gramaticale: sostantivo femminile.
Se viene selezionato un valore per il campo categoria grammaticale, vengono mostrati ulteriori criteri di ricerca che possono essere specificati per la categoria grammaticale scelta. Per esempio per verbo è possibile specificare modo, tempo e persona, etc.:
 per aggettivo invece genere e numero:
per aggettivo invece genere e numero:
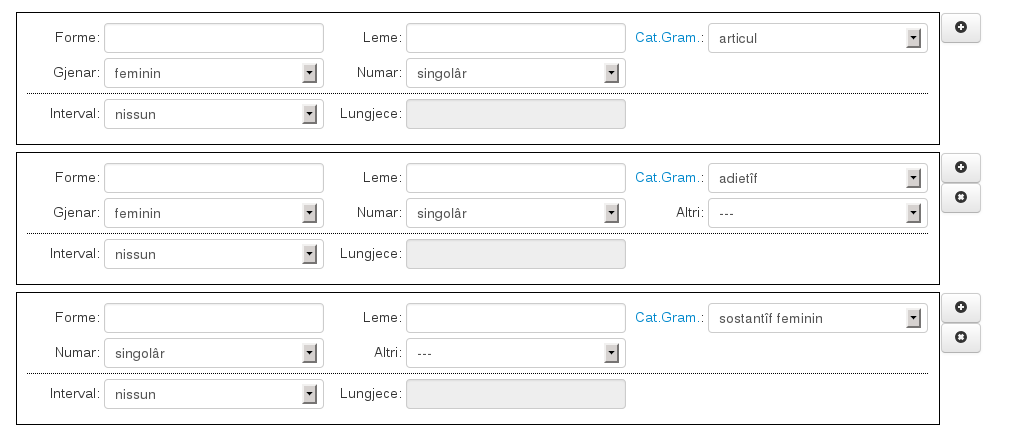
 Oltre alla singola parola, è possibile cercare una sequenza di parole di lunghezza qualsiasi. Le parole da cercare successive alla prima si aggiungono cliccando sul pulsante e possono essere rimosse con . Per esempio si può cercare la sequenza articolo femminile singolare - aggettivo femminile singolare - sostantivo femminile singolare:
Oltre alla singola parola, è possibile cercare una sequenza di parole di lunghezza qualsiasi. Le parole da cercare successive alla prima si aggiungono cliccando sul pulsante e possono essere rimosse con . Per esempio si può cercare la sequenza articolo femminile singolare - aggettivo femminile singolare - sostantivo femminile singolare:
 Tra una parola e la successiva è possibile specificare un intervallo, cioè un numero di parole intermedie tra le parole cercate. I valori per l’intervallo possono essere: nessuno (default) se si vuole che le parole seguano immediatamente, esatto per specificare un numero esatto di parole intermedie, fino a da 0 a un numero massimo di parole intermedie, qualsiasi per 0 o più parole intermedie. La sequenza viene cercata all’interno delle singole frasi. Per esempio se si cerca la sequenza articolo femminile singolare - sostantivo femminile singolare specificando per l’intervallo fino a 1
Tra una parola e la successiva è possibile specificare un intervallo, cioè un numero di parole intermedie tra le parole cercate. I valori per l’intervallo possono essere: nessuno (default) se si vuole che le parole seguano immediatamente, esatto per specificare un numero esatto di parole intermedie, fino a da 0 a un numero massimo di parole intermedie, qualsiasi per 0 o più parole intermedie. La sequenza viene cercata all’interno delle singole frasi. Per esempio se si cerca la sequenza articolo femminile singolare - sostantivo femminile singolare specificando per l’intervallo fino a 1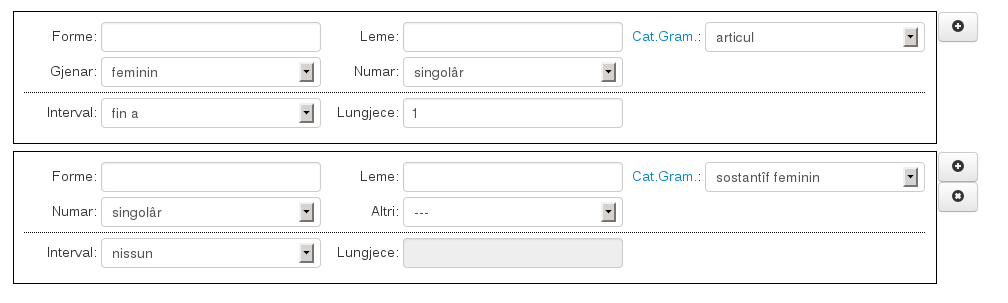 fra i risultati si ottengono: une cuantitât, la pussibilitât, la nestre realtât, une lungje storie.
fra i risultati si ottengono: une cuantitât, la pussibilitât, la nestre realtât, une lungje storie.
Filtri
I testi su cui eseguire la ricerca possono essere limitati in base all’anno di pubblicazione o all’autore, specificando valori nei relativi campi. I due filtri possono anche essere combinati: Nel caso del filtro temporale, si può limitare la ricerca a testi :
Nel caso del filtro temporale, si può limitare la ricerca a testi :
- da un certo anno in poi, specificando solo il campo ‘Da’
- fino a un certo anno, specificare solo il campo ‘A’
- all’interno di un intervallo, specificando sia il campo ‘Da’ che ‘A’
- di un singolo anno, riempiendo sia il campo ‘Da’ che ‘A’ con l’anno desiderato.

Risultati
Vengono restituite le frasi che contengono la parola o la sequenza di parole cercate. Le frasi sono raggruppate per testo, di cui è riportato titolo, autore e altre informazioni. Nella frase le parole cercate sono evidenziate in neretto:
Nella frase le parole cercate sono evidenziate in neretto:
 se si è specificato uno o più intervalli, le parole dell’intervallo sono evidenziade in grigio:
se si è specificato uno o più intervalli, le parole dell’intervallo sono evidenziade in grigio:
 Una frase può soddisfare più volte i criteri di ricerca, in questo caso ci saranno più parole/sequenze evidenziate:
Una frase può soddisfare più volte i criteri di ricerca, in questo caso ci saranno più parole/sequenze evidenziate:
 Se a sinistra della frase si trova il simbolo cliccandolo viene mostrato l’intero paragrafo in cui si trova la frase:
Se a sinistra della frase si trova il simbolo cliccandolo viene mostrato l’intero paragrafo in cui si trova la frase:

 che può essere successivamente nascosto cliccando sul simbolo . Se invece a sinistra si ha il simbolo la frase costituisce già l’intero paragrafo.
che può essere successivamente nascosto cliccando sul simbolo . Se invece a sinistra si ha il simbolo la frase costituisce già l’intero paragrafo.